
Removing duplicate rows
Overview
Here we describe a technique for removing dupicate rows from data tables. However, instead of keeping the first row, like is often done, the last row is kept instead.
Customer Sales Example
Consider the following data that shows historical sales transactions for a set of customers. You wish to filter this table to show only the last record for each customer. This is because their last entry will be their most recent order date.
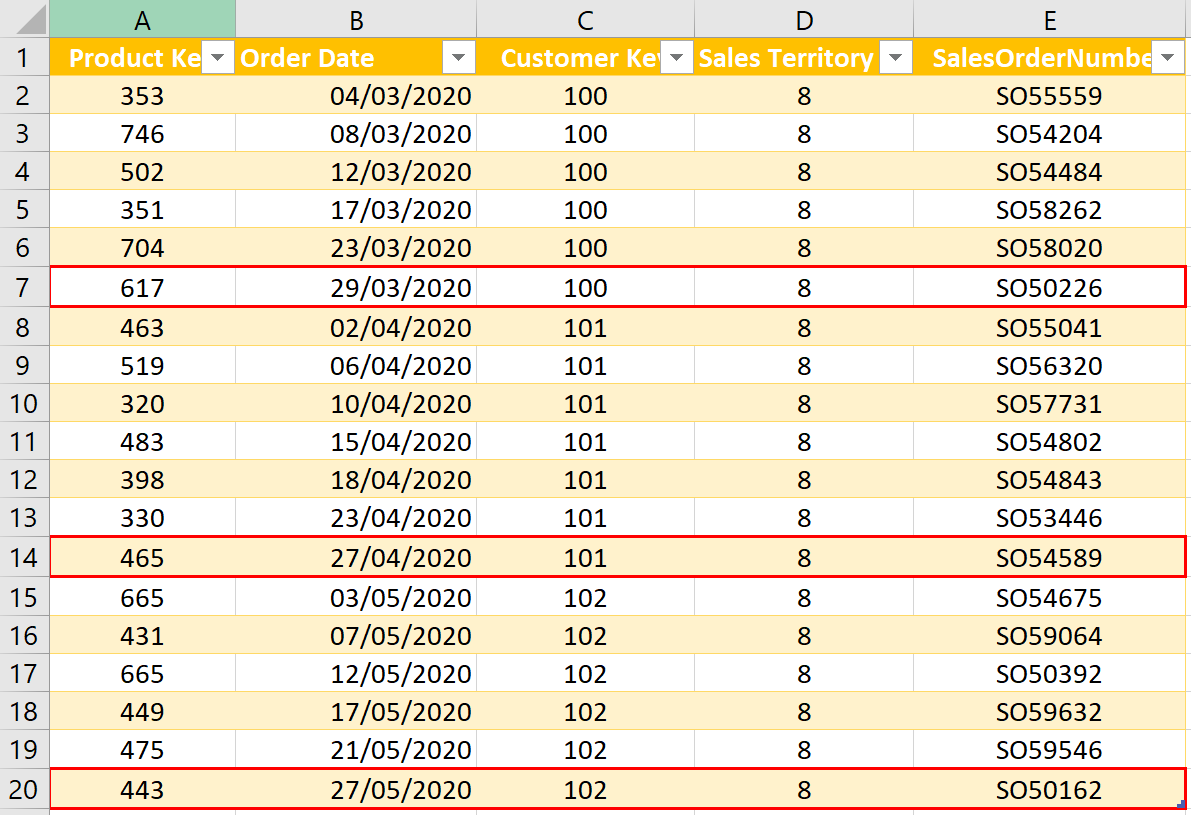
At first, the solution seems somewhat trivial. You might, for example:
- Sort the table by Order Date, in descending order
- Select the customer key column, and remove duplicates
When you do this, however, the results returned are not as expected (they do not show the correct row). See below. This is despite sorting the Order Date in Descending order, in the ‘Sorted Rows’ step!
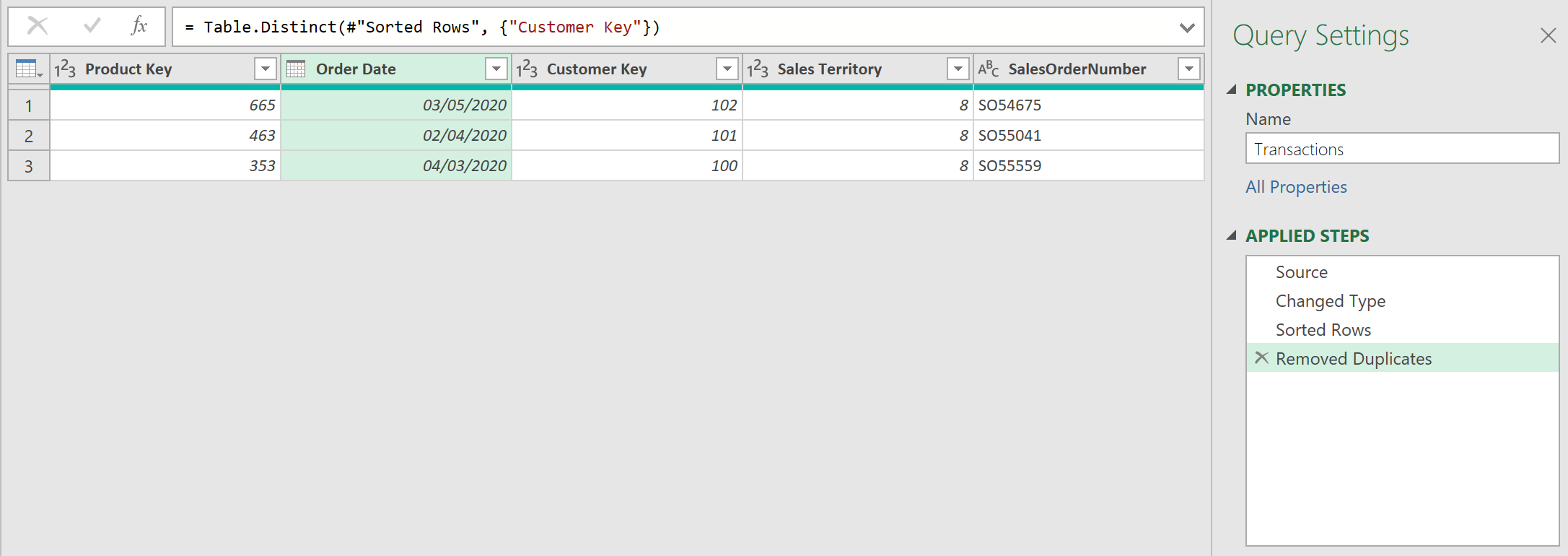
Why doesn’t it work?
The reason the above query does not work, is because Power Query uses a concept called “lazy evaluation”. This means if you add a step of code, and if that step is not technically needed, that step will never be executed.
When the ‘Order Date’ column is sorted, it is reasonable to expect that the entire table is sorted before going on to the next step. But, because of lazy evaluation, this is not what actually happens. Only the data loaded to memory is sorted.
Steps
1. Buffer the Table
To overcome this problem, you need to buffer the table to force the Query engine to load all the data into memory, thereby forcing the sort to be completed.
To achieve this, wrap the M-code, in the Sort step, with the Table.Buffer function, as shown here:
= Table.Buffer(Table.Sort(#"Changed Type",{{"Order Date", Order.Descending}}))
The resulting table returned is as follows:

Comparing this to the original data table, this is now the correct result!
Feedback
Submit and view feedback