
ETL Best Practices
Overview
Here we explain some good practices to follow with ETL when designing and building data queries.
Push transforming as close to the source as possible
Wherever possible, do any data shaping as close as possible to the data source.
There are many ways that you can shape your data (in the Microsoft BI stack).
You can always write SQL code and paste that into ETL tools to extract the data this way. The main problem with this approach is you effectively hard code a solution for a single data set. If you want to build another data set in the future, the work needs to be done again (either copy or re-write).
The data shaping tools in Power Query are designed to allow you to do whatever you need without having to rely on a third party – but only use these tools downstream if you need to.
If you have a common need for data in a particular shape and you can get support (e.g. from IT) to shape your data at the source, then there is definitely value in doing that.
Shape in Power Query, Model in Power Pivot
Power Query and Power Pivot (a data modelling tool) were built to do 2 completely different tasks.
Power Query is built for cleaning and transforming while Power Pivot is built for modelling and reporting. It is possible that you can shape your data in Power Pivot (e.g. you can write calculated columns, you can add calculated tables (in the newer versions) etc.). But best practice is to use Power Query to shape your data before/during load, and then use Power Pivot for measures and reporting.
Use a Calendar table
If you want to any sort of time calculations, get a Calendar table
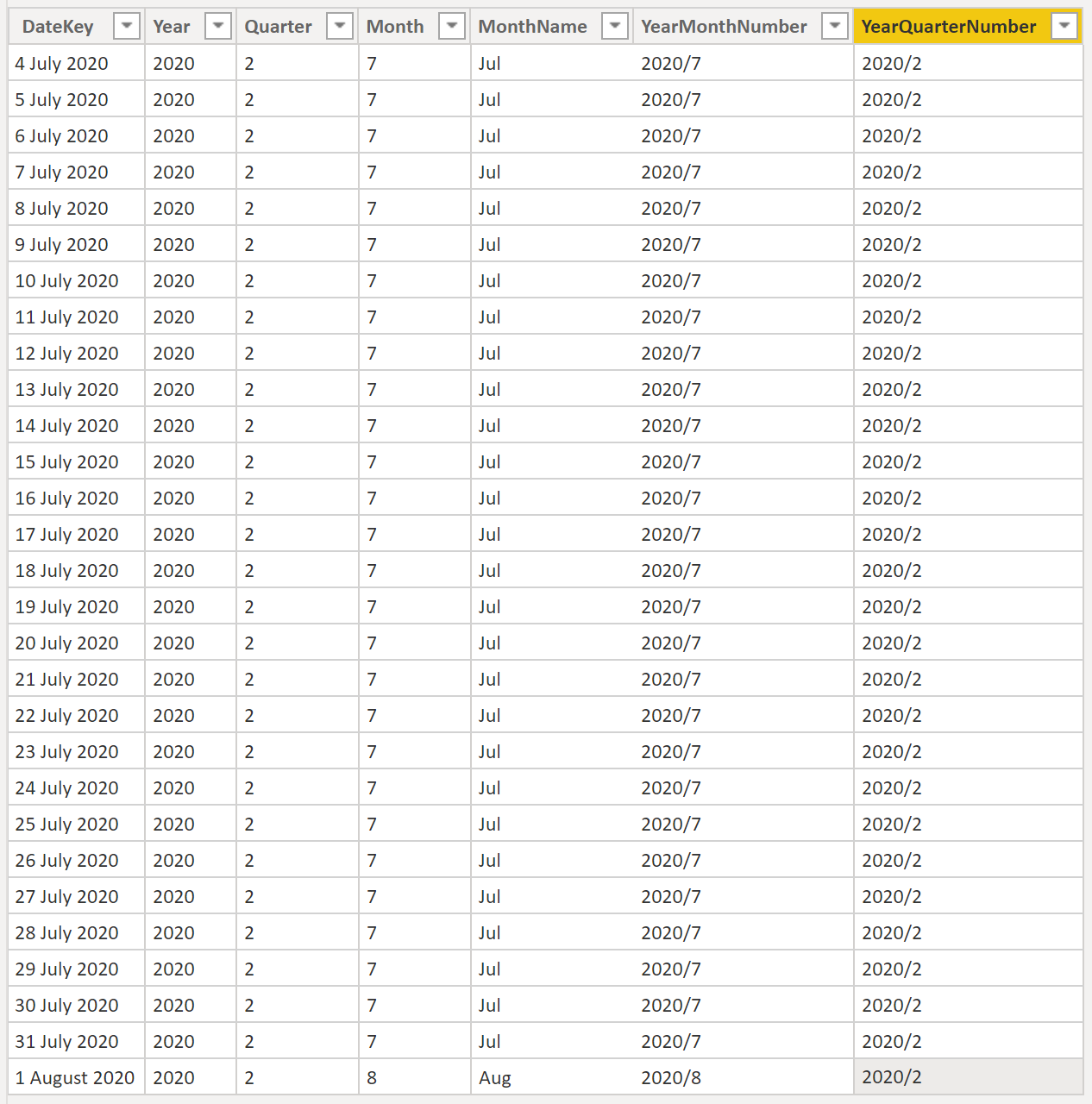
Although it is possible to analyse all your data in a single flat table without using any lookup/dimension tables, if you need to do any time related calculations, bottom line is you need a Calendar Table - a special type of lookup/dimension table for performing time intelligence functions.
A Star schema is optimal
Power Pivot is optimised to use a Star Schema table structure
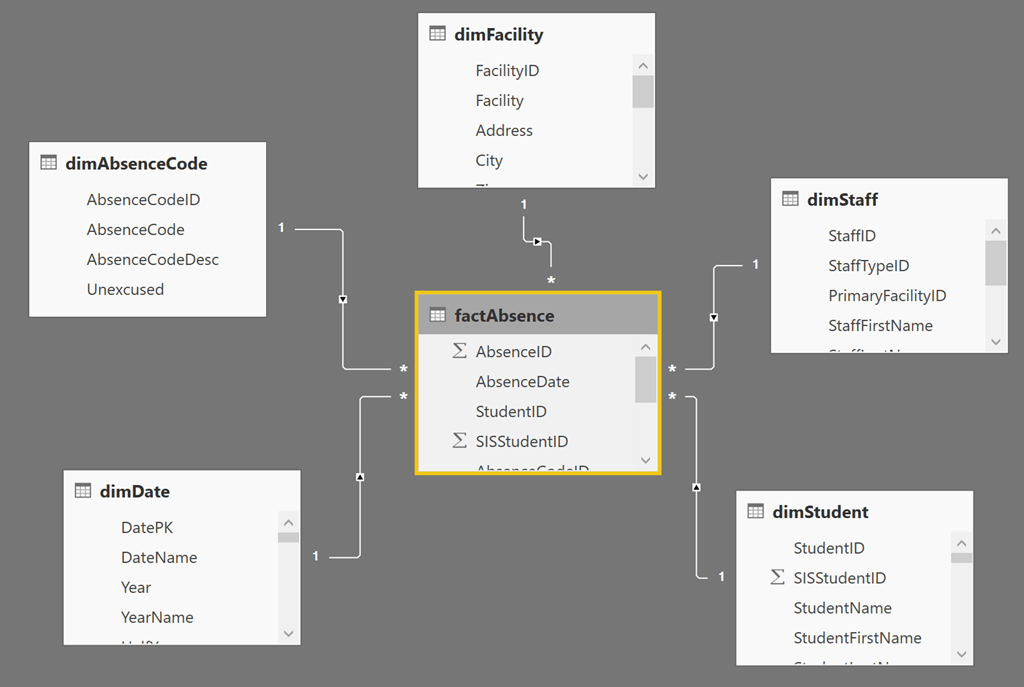
This is not to say that a Star Schema is the only layout that will work, or that other designs will always be slow, but thinking about a star schema will put you well under way to success when it comes to general data modelling and thinking about how to design and build your ETLs.
Use Long and Narrow tables
Short wide tables are generally bad for fact tables (i.e. event tables, like Sales Transactions, or Purchase Transactions) but long narrow tables are better.
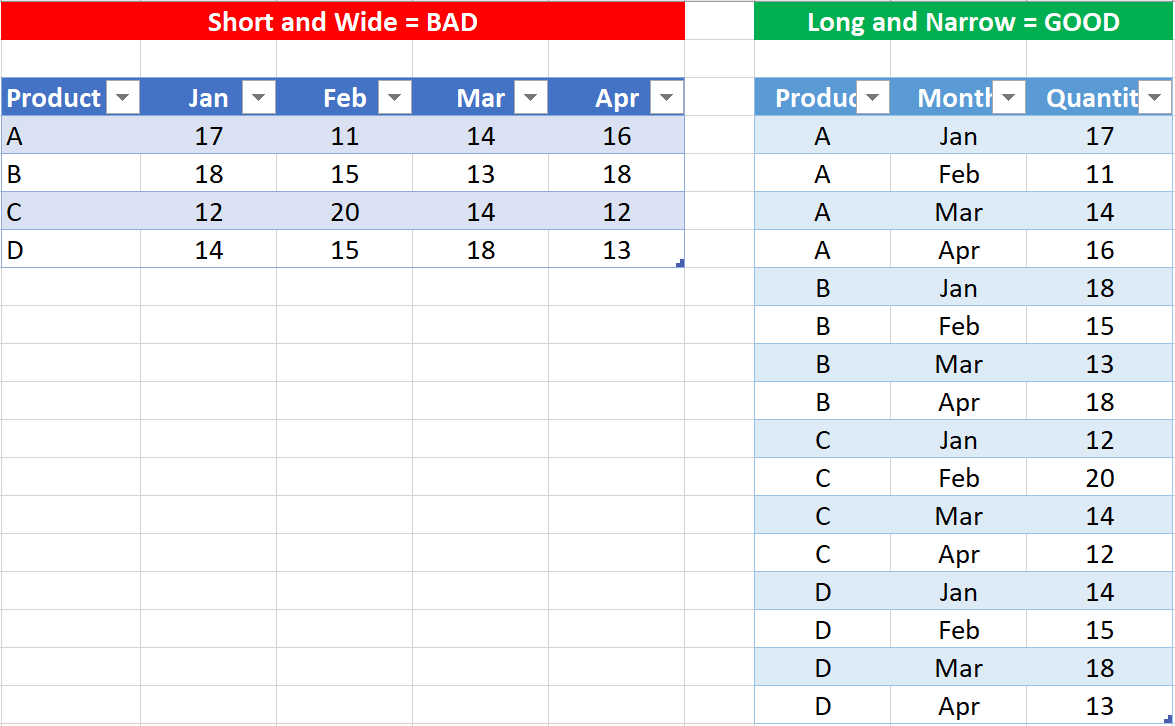
There are 2 reasons why loading data this way is a good idea.
- Power Pivot is a column store database. It uses advanced compression techniques to store the data efficiently so it takes up less space and so it is fast to access the data when needed. Long narrow tables compress better than short wide tables.
- Power Pivot is designed to quickly and easily filter your data. It is much easier/better to write one formula to add up a single column and then filter on an attribute column, than it is to write many different measures to add up each column separately.
Only load the data you need
Load all the data you need, and nothing you don’t need.
If you have data (particularly in extra columns) that you do not need to be loaded, then don’t load it. Loading data, you do not need will make your workbooks bigger and slower than they need to be.
In the old world of Excel you might have asked IT to “give you everything” because it was too hard to go back and add the missing columns of data later.
This is no longer the case – bring in all of what you need and nothing you don’t. If you need something else later, then go and get it later. Focus mainly on your large data tables – the dimension tables tend to be smaller and hence are generally less of an issue.
See also
More tips on common pitfalls to avoid when designing ETL processes can be found here:
- Dealing with slowly changing Datasets: a handful of tips on how to build ETLs that can better deal with slowly changing datasets (datasets whose structure slowly changes over time) » Read more
Feedback
Submit and view feedback